Redis除了常用的数据结构String,Hash,List,Set,Zset(sorted set),bit(位图)外,还有 HyperLogLog(2.8.9版本增加),以及Stream(5.0版本新增),下面针对他们的特性一一讲解。
String(字符串)
String是一组字节。在Redis数据库中,字符串是二进制安全的。这意味着它们具有已知长度,并且不受任何特殊终止字符的影响。可以在一个字符串中存储最多512兆字节的内容。
redis是使用C语言开发,但C中并没有字符串类型,只能使用指针或符数组的形式表示一个字符串,所以redis设计了一种简单动态字符串(SDS[Simple Dynamic String])作为底层实现:
定义SDS对象,此对象中包含三个属性:
- len buf中已经占有的长度(表示此字符串的实际长度)
- free buf中未使用的缓冲区长度
- buf[] 实际保存字符串数据的地方
所以取字符串的长度的时间复杂度为O(1),另,buf[]中依然采用了C语言的以0结尾可以直接使用C语言的部分标准C字符串库函数。
空间分配原则:当len小于IMB(1024*1024)时增加字符串分配空间大小为原来的2倍,当len大于等于1M时每次分配 额外多分配1M的空间。
由此可以得出以下特性:
- redis为字符分配空间的次数是小于等于字符串的长度N,而原C语言中的分配原则必为N。降低了分配次数提高了追加速度,代价就是多占用一些内存空间,且这些空间不会自动释放。
- 二进制安全的
- 高效的计算字符串长度(时间复杂度为O(1))
- 高效的追加字符串操作。
Hash(哈希)
哈希是键值对的集合。在Redis中,哈希是字符串字段和字符串值之间的映射。因此,它们适合表示对象。
redis的散列可以存储多个键 值 对之间的映射,散列存储的值既可以是字符串又可以是数字值,并且用户同样可以对散列存储的数字值执行自增操作或者自减操作。散列可以看作是一个文档或关系数据库里的一行。hash底层的数据结构实现有两种:
1.一种是ziplist,其结构参考下文,当存储的数据超过配置的阀值时就是转用hashtable的结构。这种转换比较消耗性能,所以应该尽量避免这种转换操作。同时满足以下两个条件时才会使用这种结构:
当键的个数小于hash-max-ziplist-entries(默认512)
当所有值都小于hash-max-ziplist-value(默认64)
每个哈希可以存储多达232 – 1亿个字段 – 值对。
2.另一种就是hashtable。这种结构的时间复杂度为O(1),但是会消耗比较多的内存空间。
List(列表)
Redis列表定义为字符串列表,按插入顺序排序。可以将元素添加到Redis列表的头部或尾部。
redis对键表的结构支持使得它在键值存储的世界中独树一帜,一个列表结构可以有序地存储多个字符串,拥有例如:lpush lpop rpush rpop等等操作命令。在3.2版本之前,列表是使用ziplist和linkedlist实现的,在这些老版本中,当列表对象同时满足以下两个条件时,列表对象使用ziplist编码:
列表对象保存的所有字符串元素的长度都小于64字节列表对象保存的元素数量小于512个当有任一条件 不满足时将会进行一次转码,使用linkedlist。
而在3.2版本之后,重新引入了一个quicklist的数据结构,列表的底层都是由quicklist实现的,它结合了ziplist和linkedlist的优点。按照原文的解释这种数据结构是【A doubly linked list of ziplists】意思就是一个由ziplist组成的双向链表。那么这两种数据结构怎么样结合的呢?
ziplist的结构
由表头和N个entry节点和压缩列表尾部标识符zlend组成的一个连续的内存块。然后通过一系列的编码规则,提高内存的利用率,主要用于存储整数和比较短的字符串。可以看出在插入和删除元素的时候,都需要对内存进行一次扩展或缩减,还要进行部分数据的移动操作,这样会造成更新效率低下的情况。
linkedlist的结构
意思为一个双向链表,和普通的链表定义相同,每个entry包含向前向后的指针,当插入或删除元素的时候,只需要对此元素前后指针操作即可。所以插入和删除效率很高。但查询的效率却是O(n)[n为元素的个数]。
quicklist的结构
了解了上面的这两种数据结构,我们再来看看上面说的“ziplist组成的双向链表”是什么意思?实际上,它整体宏观上就是一个链表结构,只不过每个节点都是以压缩列表ziplist的结构保存着数据,而每个ziplist又可以包含多个entry。也可以说一个quicklist节点保存的是一片数据,而不是一个数据。总结:
整体上quicklist就是一个双向链表结构,和普通的链表操作一样,插入删除效率很高,但查询的效率却是O(n)。不过,这样的链表访问两端的元素的时间复杂度却是O(1)。所以,对list的操作多数都是poll和push。
每个quicklist节点就是一个ziplist,具备压缩列表的特性。
在redis.conf配置文件中,有两个参数可以优化列表:
list-max-ziplist-size 表示每个quicklistNode的字节大小。默认为-2 表示8KB
list-compress-depth 表示quicklistNode节点是否要压缩。默认是0 表示不压缩
列表的最大长度为232 – 1个元素(每个列表超过40亿个元素)。
Set(集合)
redis的集合和列表都可以存储多个字符串,它们之间的不同在于,列表可以存储多个相同的字符串,而集合则通过使用散列表(hashtable)来保证自已存储的每个字符串都是各不相同的(这些散列表只有键,但没有与键相关联的值),redis中的集合是无序的。还可能存在另一种集合,那就是intset,它是用于存储整数的有序集合,里面存放同一类型的整数。共有三种整数:int16_t、int32_t、int64_t。查找的时间复杂度为O(logN),但是插入的时候,有可能会涉及到升级(比如:原来是int16_t的集合,当插入int32_t的整数的时候就会为每个元素升级为int32_t)这时候会对内存重新分配,所以此时的时间复杂度就是O(N)级别的了。注意:intset只支持升级不支持降级操作。
intset在redis.conf中也有一个配置参数set-max-intset-entries默认值为512。表示如果entry的个数小于此值,则可以编码成REDIS_ENCODING_INTSET类型存储,节约内存。否则采用dict(字典)的形式存储。
在Redis中,添加,删除和查找的时间复杂度是O(1),集合中的最大成员数为2^32 – 1个元素(每个列表超过40亿个元素)。
Sorted Set(有序集合)
Redis有序集合类似于Redis集合,也是一组非重复的字符串集合。但是,排序集的每个成员都与一个分数相关联,该分数用于获取从最小到最高分数的有序排序集。虽然成员是独特的,但可以重复分数。
有序集合和散列一样,都用于存储键值对:有序集合的键被称为成员(member),每个成员都是各不相同的。有序集合的值则被称为分值(score),分值必须为浮点数。有序集合是redis里面唯一一个既可以根据成员访问元素(这一点和散列一样),又可以根据分值以及分值的排列顺序访问元素的结构。它的存储方式也有两种:
是ziplist结构。与上面的hash中的ziplist类似,member和score顺序存放并按score的顺序排列
- 另一种是skiplist与dict的结合。
skiplist是一种跳跃表结构,用于有序集合中快速查找,大多数情况下它的效率与平衡树差不多,但比平衡树实现简单。redis的作者对普通的跳跃表进行了修改,包括添加spanailbackward指针、score的值可重复这些设计,从而实现排序功能和反向遍历的功能。
一般跳跃表的实现,主要包含以下几个部分:
- 表头(head):指向头节点
- 表尾(tail):指向尾节点
- 节点(node):实际保存的元素节点,每个节点可以有多层,层数是在创建此节点的时候随机生成的一个数值,而且每一层都是一个指向后面某个节点的指针。
- 层(level):目前表内节点的最大层数
- 长度(length):节点的数量。
跳跃表的遍历总是从高层开始,然后随着元素值范围的缩小,慢慢降低到低层。
跳跃表的原理请参考我前面的文章:数据结构与算法 -- 跳跃表(SkipList)
前面也说了,有序列表是使用skiplist和dict结合实现的,skiplist用来保障有序性和访问查找性能,dict就用来存储元素信息,并且dict的访问时间复杂度为O(1)。
Bit(位图)
位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。我们可以使用普通的 get/set 直接获取和设置整个位图的内容,也可以使用位图操作 getbit/setbit等将 byte 数组看成「位数组」来处理。
Redis 的位数组是自动扩展,如果设置了某个偏移位置超出了现有的内容范围,就会自动将位数组进行零扩充。
HyperLogLog
HyperLogLog算法经常在数据库中被用来统计某一字段的Distinct Value(即不重复值,下文简称DV)
HyperLogLog算法来源于论文《HyperLogLog the analysis of a near-optimal cardinality estimation algorithm》,可以使用固定大小的字节计算任意大小的DV,如果你感兴趣可以试着百度一下,本文不做深究,只做简单介绍
基数就是指一个集合中不同值的数目,比如[a,b,c,d]的基数就是4,[a,b,c,d,a]的基数还是4,因为a重复了一个,不算。基数也可以称之为Distinct Value,简称DV。HyperLogLog算法就是用来计算基数的。
Stream
stream是一个看起来比pubsub可靠多的消息队列。pubsub不靠谱? 很不靠谱,网络一断或buffer一大就会主动清理数据。stream的设计参考了kafka的消费组模型
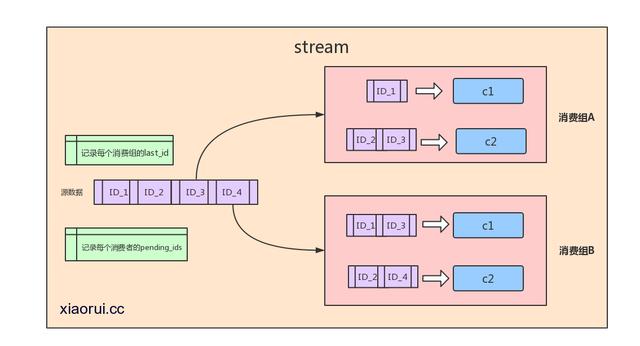
用过kafka的人再看这图就很好理解了。源数据用来存放stream的生产出来的数据,数据是按照有seq_id序排列的。 redis会记录stream里每个消费组最后消费的last_id及还没有返回ack确认的id数据。每个消费组都有一个last_id, 也就是说 每个消费组都可以消费同一条数据,每个消费组里可以有多个消费者,多个消费组的关系是相互竞争的。
比如同一条数据,a系统会用,b系统也会用到,那么这时候要用消费组了。 a系统如果只有一个消费者会造成吞吐不够的情况,redis stream consumer group可以在同一个消费组里有多个消费者,consumer消费者多了,吞吐自己就上来了。 redis stream是可以保证这些操作原子性的。
stream又维护了一个pending_ids的数据,他的作用是维护消费者的未确认的id,比如消费者get了数据,但是返回给你的时候网络异常了,crash了,又比如消费者收到了,但是crash掉了? redis stream维护了这些没有xack的id. 我们可以xpending来遍历这些数据,xpending是有时间信息的,我们可以在代码层过滤一个小时之前还未xack的id。
至于底层细节,我们后续慢慢给大家解开它的面纱!本文点到为止。
适用场景分析
- String,redis对于KV的操作效率很高,可以直接用作计数器。例如,统计在线人数等等,另外string类型是二进制存储安全的,所以也可以使用它来存储图片,甚至是视频等。
- hash,存放键值对,一般可以用来存某个对象的基本属性信息,例如,用户信息,商品信息等,另外,由于hash的大小在小于配置的大小的时候使用的是ziplist结构,比较节约内存,所以针对大量的数据存储可以考虑使用hash来分段存储来达到压缩数据量,节约内存的目的,例如,对于大批量的商品对应的图片地址名称。比如:商品编码固定是10位,可以选取前7位做为hash的key,后三位作为field,图片地址作为value。这样每个hash表都不超过999个,只要把redis.conf中的hash-max-ziplist-entries改为1024,即可。
- list,列表类型,可以用于实现消息队列,也可以使用它提供的range命令,做分页查询功能。
- set,集合,整数的有序列表可以直接使用set。可以用作某些去重功能,例如用户名不能重复等,另外,还可以对集合进行交集,并集操作,来查找某些元素的共同点
- zset,有序集合,可以使用范围查找,排行榜功能或者topN功能。
- 位图,可以用来实现签到功能
- Stream,消息队列
- HyperLogLog,统计基数的场景都适用
OK,篇幅不宜过长,谢谢你的浏览!!喜欢就关注一下吧。
![领域]在实践中展望。。。(写给DDD注释版)](/images/no-images.jpg)